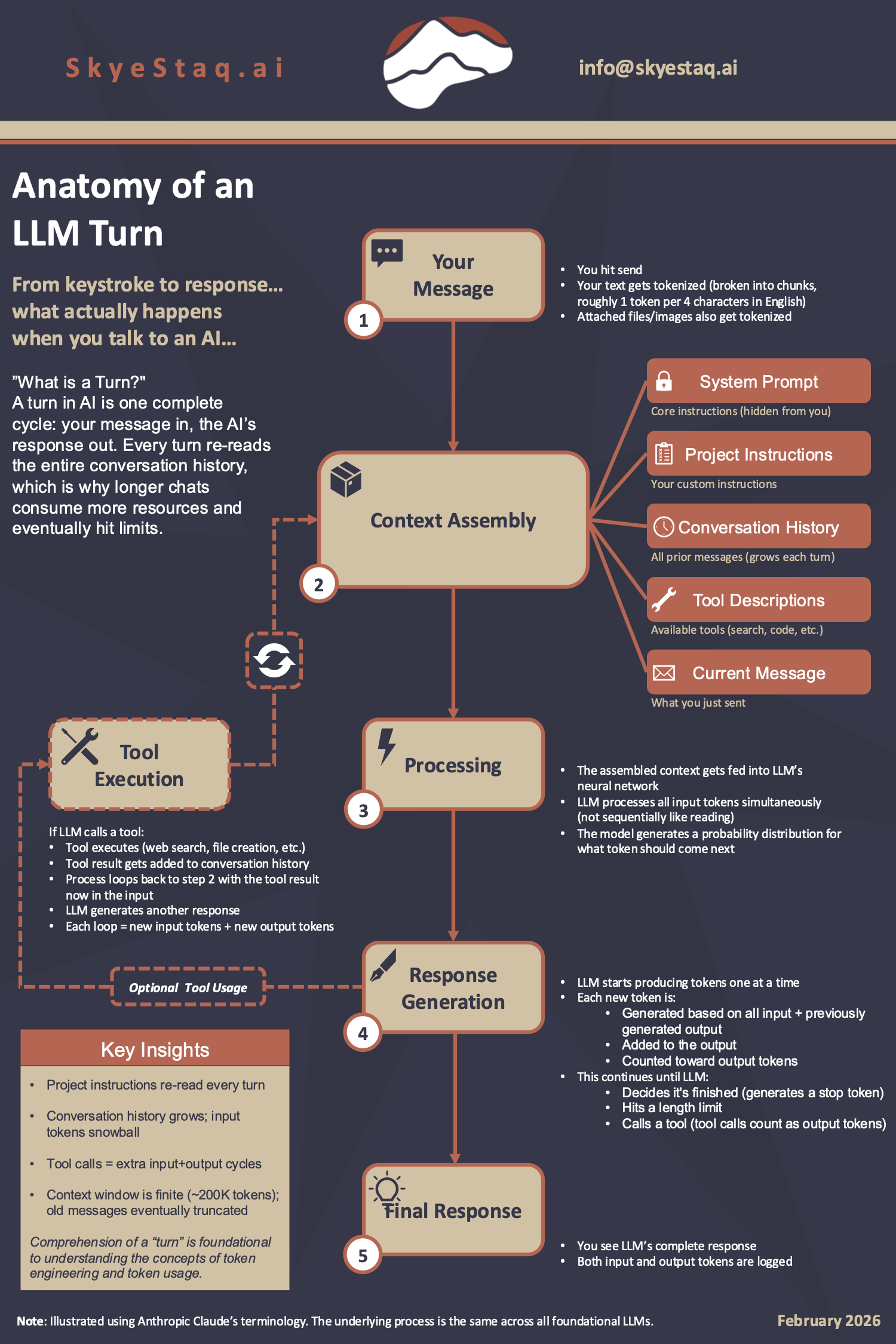
Every time you send a message to an AI, a precise sequence of events unfolds. Most users never see it. Understanding what happens inside that cycle isn't just interesting; it's foundational to using AI more effectively, managing costs, and knowing why longer conversations behave differently than fresh ones. This infographic maps the full journey of a single turn.
Click to enlarge
Key Takeaways
Comprehension of a "turn" is foundational to understanding the concepts of token engineering and token usage. Here are the four things worth internalizing:
- Project instructions are re-read every turn. Any custom instructions you've set aren't cached; they're fed into the model fresh with every single message you send.
- Conversation history grows; input tokens snowball. Every prior message in the thread gets included in the context each turn. The longer the conversation, the more tokens are consumed just to carry the history forward.
- Tool calls add extra input and output cycles. When an AI uses a tool (like web search or code execution), that triggers a full additional loop; the tool result re-enters as new input, generating new output tokens before you see a final response.
- The context window is finite. Most leading models support roughly 200,000 tokens of context. Once that limit is approached, older messages get truncated, which can cause the AI to "forget" earlier parts of the conversation.